

Gemini API
それではAPI取得の為の下準備をするよ。まずは[Google Cloud プロジェクト]へGOだ!
Google Cloud プロジェクト

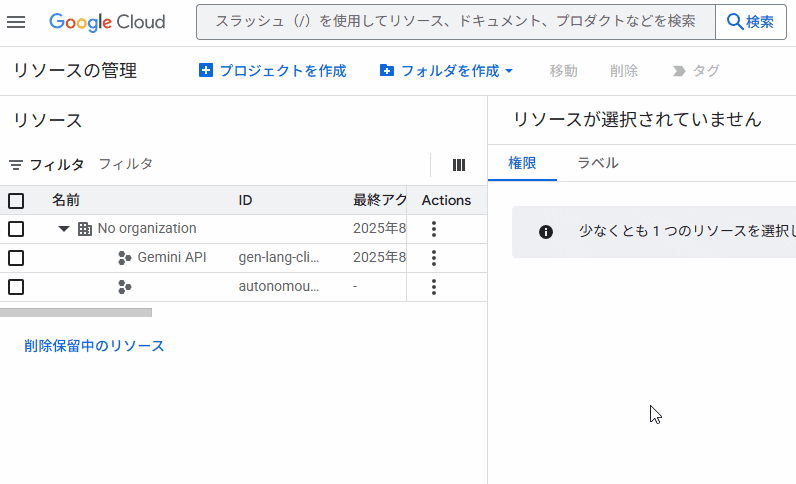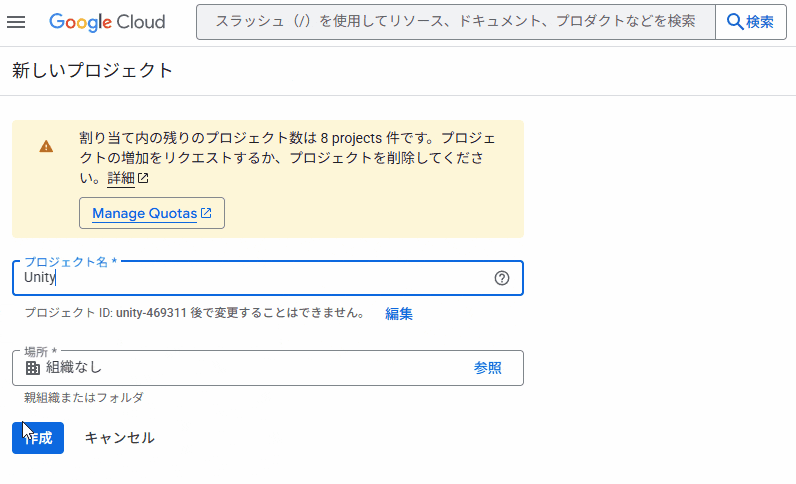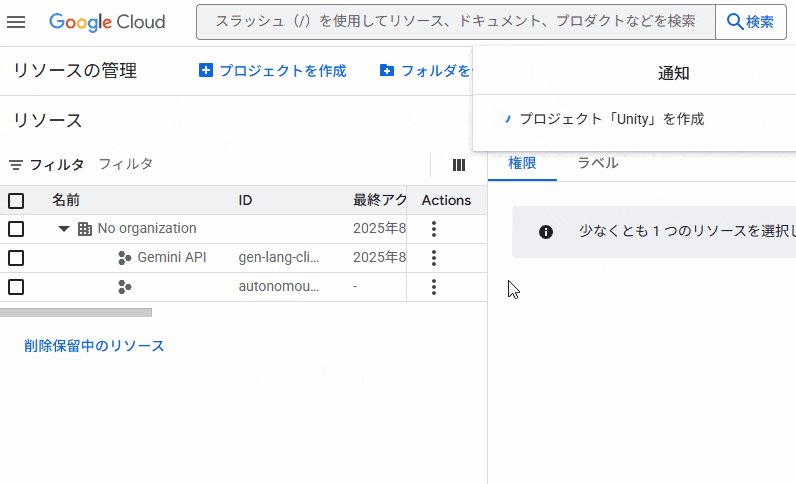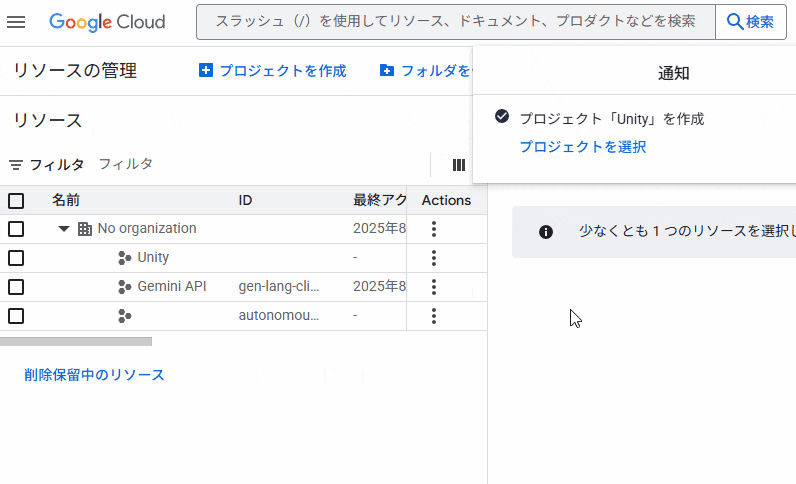
[プロジェクト作成]→[プロジェクト名]にUnityと命名しよう。Geminiはgoogleが提供しているAIなんだ。だから、どのプロジェクトで使うの?と聞かれるので、その時に今作ったプロジェクト名を使うことになるよ
Gemini TOPページ

ではではgeminiのAPIを取得するよ。アカウントを登録は終わったかな?トップページから[Get API key]を押下してね
はいよ。これ見よがしに青いボタンで目立ってるね!
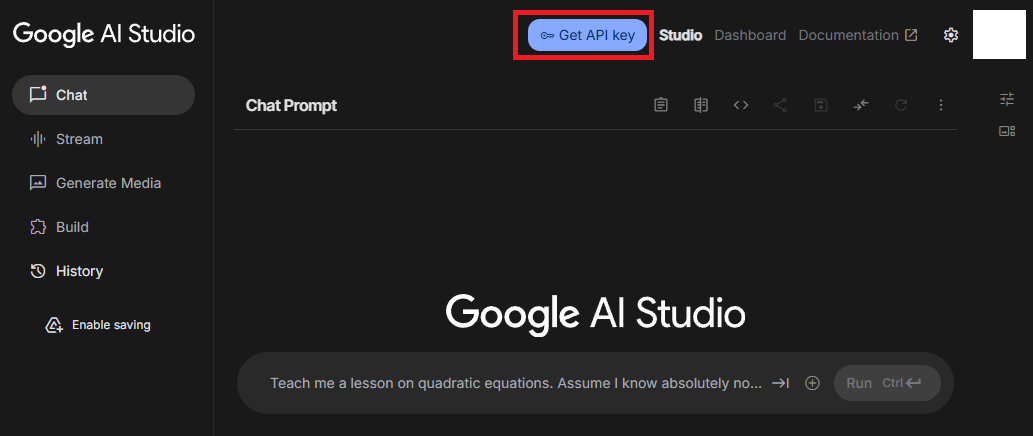
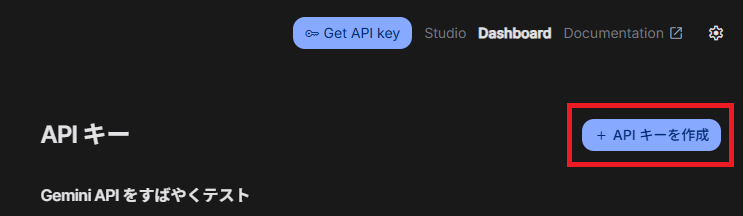
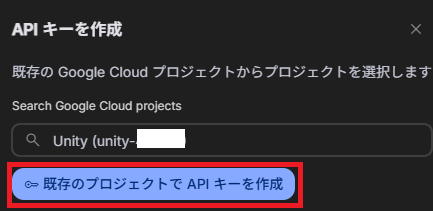

APIキーを取得できたね。これは個人のものだから他の人と共有しないように注意が必要だ。後で使うのでどこかに保存しておいてね。もしも忘れてしまった場合はGeminiのページで確認できるからね

おっけー!しっかりと保存しとくね!
VSCodeでAPIをContinueに設定
Continueに使用サービスの登録とAPIの設定しよっか
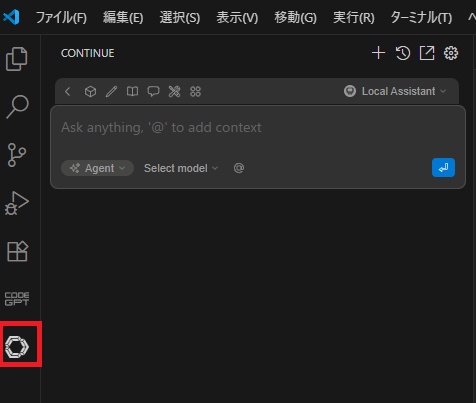
登録するの多いよー!
そりゃあ、サービスを提供している会社だってボランティアしてるんじゃないんだから、その会社のアカウントを作るのは当たり前のことでしょ。続きやっていくよー
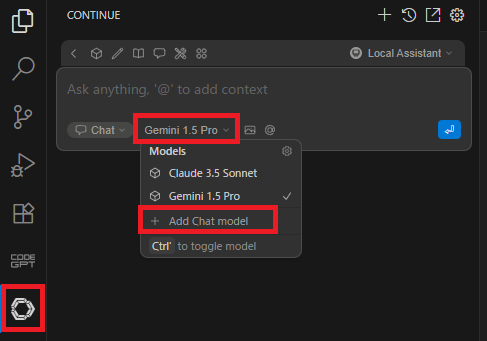
[Continue]のチャット下部にあるドロップダウンから、[Add Chat Model]を押下しよう。もう少しでContinueの設定は終わりだから頑張ろう!
がんばろー!
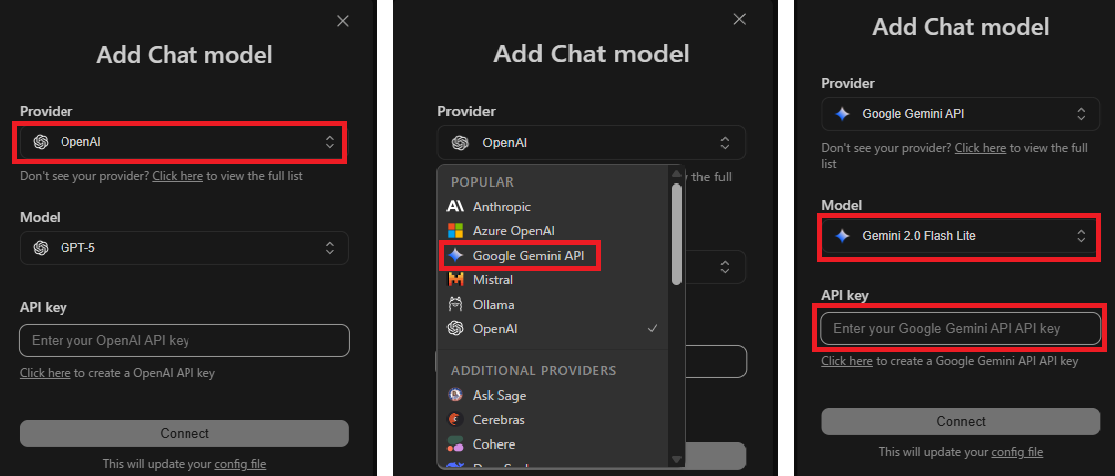
[Provider]から今回APIを取得してきたGeminiAPIは[google AI Studio]のやつだな。Modelは[2.0 Flash Lite]を選ぼうか
できたっ!やったー!
追加した時に[config.yaml]というファイルが自動で開かなかったかい?ついでに[2.0 Flash]も追加しておこうか
name: Local Assistant
version: 1.0.0
schema: v1
models:
- name: Gemini 2.0 Flash Lite
provider: gemini
model: gemini-2.0-flash-lite
apiKey: ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
- name: Gemini 2.0 Flash
provider: gemini
model: gemini-2.0-flash
apiKey: ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
default_model: Gemini 2.0 Flash Lite
context:
- provider: code
- provider: docs
- provider: diff
- provider: terminal
- provider: problems
- provider: folder
- provider: codebase
うん、ちゃんとなってる!
おめでとう頑張ったね……それじゃ成果を確認しようか!
動作確認
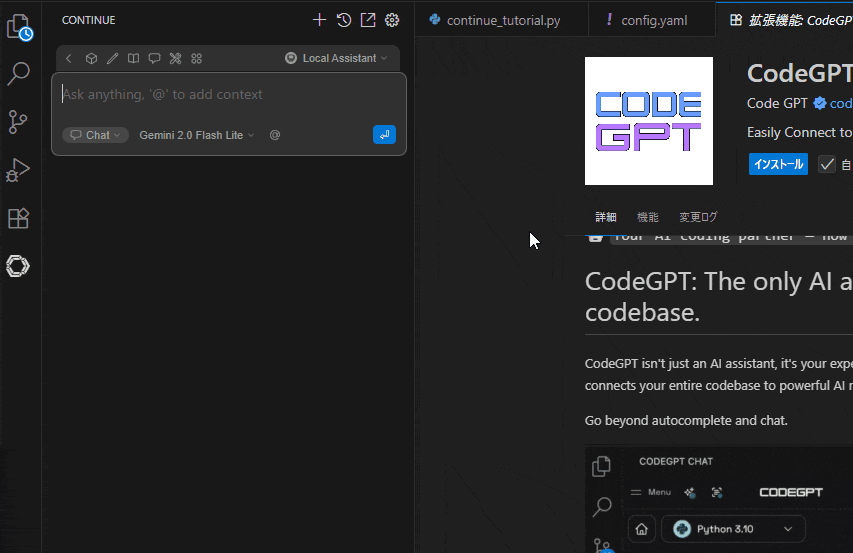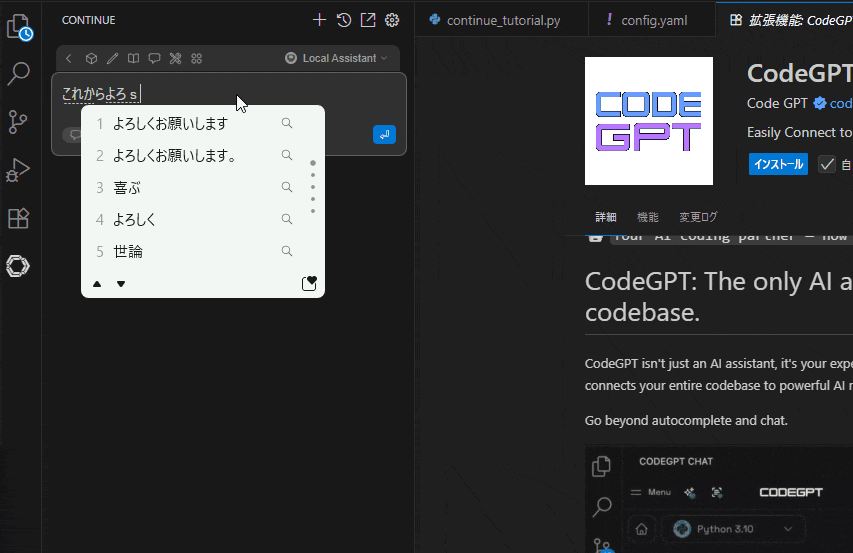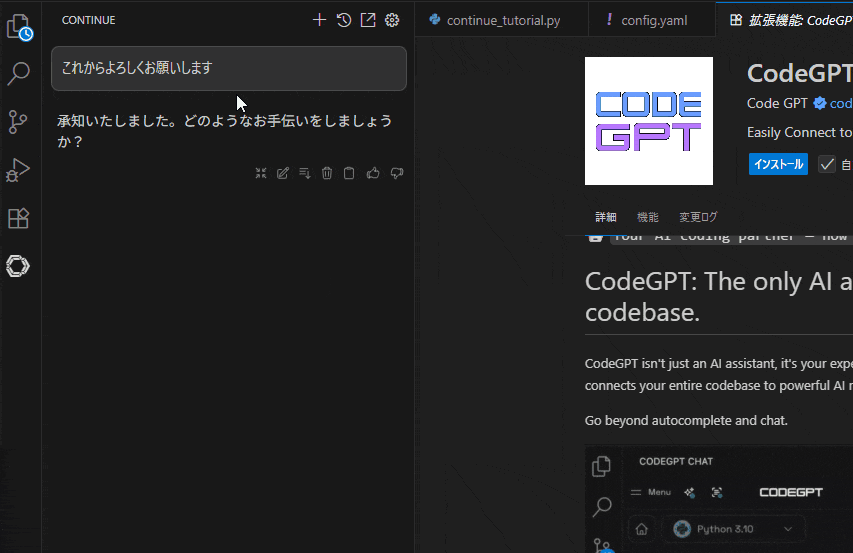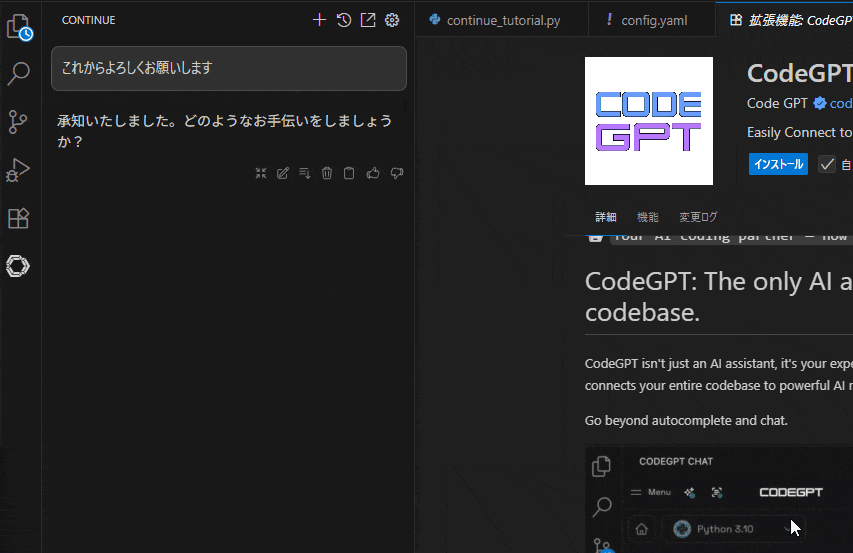
挨拶したら反応したあああ!?
やったぜ
VSCodeでAI活用まとめ
- 2025年8月時点で、APIを介して実用的に使えるAIはGeminiのみ(無料枠的に)
- chatGPTはwebから使う(3.5は無制限での利用可)
- 他のモデル(Claude, GPT, Mistral)は API利用は必ず課金前提
よくここまで頑張った。お前の苦労をずっと見ていたぞ。最後に[gemini 2.5 flash]と[gemini 2.5 flash Lite]を比較して終わろう
Gemini 2.5 Flash vs Flash-Lite 比較表
| 特性 | Gemini 2.5 Flash | Gemini 2.5 Flash-Lite |
|---|---|---|
| 目的・特徴 | 高速・効率・Reasoning型の汎用モデル | コスト重視・超高速・高スループットが必要な処理向け |
| スループットの制限 | 10 RPM、250 RPD、約25万 TPM(月あたり) | 15 RPM、1,000 RPD、約25万 TPM |
| 性能 vs コスト | 高性能だが無料枠はやや厳しめ | 性能はほどほど、コスト効率と利用量に優れる |
| 推奨使用シーン | 反応の質・Reasoning精度重視/少量高精度タスク向け | 高頻度・大量処理/チャットボット・分類処理に最適 |
| 最新情報 | 一般利用可能で優れたバランスを実現 | 同様にGA提供中、より低レイテンシーかつ安価 |
Gemini API:主要モデルの無料枠制限比較
| モデル名 | リクエスト制限(RPM / RPD) | トークン/日 (TPM) |
|---|---|---|
| Gemini 2.5 Flash | 10 RPM / 250 RPD | 最大 250,000 TPM |
| Gemini 2.5 Flash-Lite | 15 RPM / 1,000 RPD | 最大 250,000 TPM |
| Gemini 2.0 Flash | 15 RPM / 200 RPD | 最大 1,000,000 TPM |
| Gemini 2.0 Flash-Lite | 30 RPM / 200 RPD | 最大 1,000,000 TPM |
-
RPM (Requests Per Minute)
1分あたりのリクエスト上限 -
RPD (Requests Per Day)
1日あたりのリクエスト上限 -
TPM (Tokens Per Minute)
1分あたりのトークン処理上限。実質的な制限として捉えると便利です。
どちらを選ぶべき?
-
高精度タスクに注力したいなら → Gemini 2.5 Flash
少ないリクエストで深い回答や推論を期待するならこちら。 -
大量リクエストやコストを重視するなら → Gemini 2.5 Flash-Lite
成果は十分で、頻繁な利用や負荷の高い処理にも安定対応。
たとえば、Unity開発で短いスクリプト補完やUI説明を大量に欲しいという場合は Flash-Liteがぴったり。一方、複雑なアルゴリズム設計やエラー原因分析など、「質」を重視する場面では Flash を選択するのがおすすめ
無料で使えるAIまとめ
Chatgpt(WEB)

Google AI Studio(Gemini WEB)
今回設定したgemini(Gemini API)
※もし、APIの無料枠が無くなってしまった場合は、WEBから他のモデルなどを利用するようにしましょう。
とりあえず、お疲れ様だね。難しいとこは終えることができたね
よーし、これからばりばりAI使っていくぞ~!
次のページ
※コメントポリシーはこちらから。